Synchronization
In .NET 4.0, a lot of great additions have
been made in the form of enhancing existing synchronization primitives
as well as adding new ones.
Thread Pool and Tasks
The thread pool that is
available in CLR 2.0 provides a nice mechanism of queuing up work and
having that work eventually be executed by one of the threads in the
thread pool. The great thing about the thread pool is that you can leave
the decision of which thread gets to execute which work item up to the
underlying runtime. This approach works well because the thread pool has
the most knowledge about what is being executed and which threads are
the most appropriate to serve other requests. Having said that, at the
end of the day, the runtime really only knows that it has a queue of
“work items” and a bunch of threads to service those requests. This can
lead to less than optimal performance because work items that, for
example, are related can’t be ordered properly for optimal performance
(after all, the thread pool picks up new requests in a FIFO fashion).
Furthermore, although an implementation detail, the data structures
associated with the queue itself, as well as the cost of locking that
queue every time a work item is enqueued and dequeued, adds to the
overall cost. To address the locking inefficiency, .NET 4.0 switched to a
lock-free data structure to avoid the performance cost of constantly
locking and unlocking. Additionally, it changed the data structure by
making it more GC friendly, thereby speeding up the collection of these
data structures. Although these two improvements will yield gains in
performance, it still doesn’t address the fact that the thread pool
knows nothing about the work items themselves. They are simply treated
as opaque items in a FIFO order. If we could somehow tell the thread
pool more about the work items, the order in which they were serviced
could be optimally organized. It turns out that .NET 4.0 addresses this
problem also by introducing what is known as the Task Parallel library
(TPL). Although we won’t go into the details of the TPL (System.Threading.Tasks),
suffice to say that it exposes a much richer API set that allows the
details of work items to be more clearly defined, thereby allowing more
efficient scheduling and execution of the tasks.
Monitor
The fundamental problem was in the IL that was generated by the compiler. More specifically, a nop instruction was inserted before the try block. The net result is that if the ThreadAbortException was thrown while executing the nopfinally
clause would never execute and hence the lock would never be released.
To solve this problem, .NET 4.0 introduces an overloaded version of the Monitor.Enter method: instruction, the
public static void Enter(Object obj, ref bool lockTaken)
The lockTaken argument is true if the lock was in fact acquired; otherwise, it is false. This new overloaded method allows the following pattern:
bool acquired=false;
try
{
Monitor.Enter(objToLock, ref acquired);
// Do work while holding the lock
}
Finally
{
if(acquired)
{
Monitor.Exit(objToLock);
}
}
The IL that the compiler now generates for a lock
statement has also been updated to follow the same pattern and always
takes the lock inside of the try statement, thereby guaranteeing that
the lock is released in the finally clause even in the presence of ThreadAbortExceptions.
Barrier
A Barrier (System.Threading.Barrier)
can best be thought of as a way of sequencing a series of operations by
using one or more explicit checkpoints that have to be reached before
the operation is complete. For example, let’s say that we have a task
that requires a number of buffers to be populated followed by using the
data across the buffers in various calculations. Before the second
phase (performing calculations) can start, all the buffers need to be
filled in. By creating a Barrier that contains X number of participants,
each participant can’t execute each of the phases (write, read) and use
the barrier after each phase to wait for all the other participants
before resuming.
CountdownEvent
The CountdownEvent class (System.Threading.CountdownEvent) is a counting event that is only signaled when its count reaches 0.
ManualResetEventSlim
The ManualResetEventSlim class (System.Threading.ManualReset EventSlim) is similar to the already existing ManualResetEvent. The key difference is that the newly introduced ManualResetEventSlim
primitive will utilize spinning first in order to acquire a lock that
has already been acquired. If, within a given spin threshold, the lock
still can’t be acquired, it enters a wait state (such as the case with ManualResetEvent).
Because entering a wait state is not required by default, the data
structures that are required for this wait state need not be allocated,
which is why the name includes the word Slim. Please note that in contrast to the ManualResetEvent class, the Slim version can only be used intraprocess.
SemaphoreSlim
Much like the ManualResetEventSlim discussed, the Semaphore class also contains an efficient and Slim (spinning) version called SemaphoreSlimSystem.Threading.SemaphoreSlim). Please note that in contrast to the Semaphore class, the Slim version can only be used intraprocess. (
SpinWait and SpinLock
In cases where the
amount of time that any given lock is held is small, spinning may be a
more resource-efficient way of waiting for a lock to be released. The
primary reason is that rather than allocate the resource needed (such as
an event) to enter a wait state, the thread can simply spin and check
to see if the lock has become available. The cost of spinning, in
short-lived lock scenarios, is far smaller than the equivalent resources
required for an efficient wait. The SpinLock class (System.Threading) can be used when you want to utilize only the spinning aspects of a lock, whereas the SpinWait (System.Threading) class can be used if you want to spin for a little bit before entering a wait state.
Interoperability
Just as other areas of CLR
4.0 have undergone some dramatic improvements, so has interoperability.
One of the major headaches with doing COM interoperability is the use of
the primary interop assembly (PIA). The PIA is a separate
assembly that acts as a managed code “proxy” to the underlying COM
object. The biggest drawback with a PIA is that it is in fact a separate
assembly that has to accompany the application using it, which causes
problems in the area of deployment such as versioning and size. For
example, to use a PIA, the entire PIA has to be deployed with the
application even if only small portions of the PIA are actually being
used. To address this problem, CLR 4.0 introduces what is known as COM
interop via NoPIA (No Primary Interop Assembly). This can be achieved by
embedding all the necessary information that is required to call the
COM object into the application itself, thereby eliminating the need for
separate deployment of the PIA as well as taking the size hit if only
portions of it are being used.The example required a separate PIA
assembly to function. To use the new NoPIA with the same example, we can
use the exact same code with the minor exception of how the application
is built. Rather than referencing the PIA assembly as part of the
build, we now can use the /link
compiler switch (new in CLR 4.0) to specify a PIA assembly and tell the
compiler to embed the metadata into our application. Please note that it
will only embed the metadata that is being used in the application,
hence reducing the size requirements drastically if only small portions
are being utilized.
Another major enhancement
is around making it easier to write P/Invoke signatures. A new tool was
created called the P/Invoke Interop Assistant and is available on
CodePlex:
http://www.codeplex.com/clrinterop
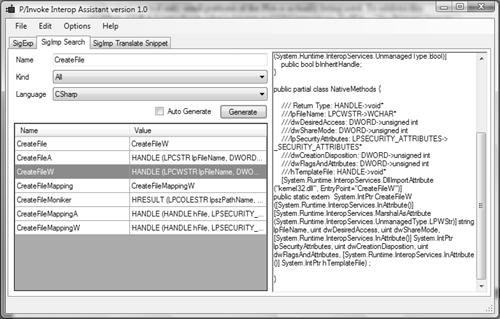
The P/Invoke Interop Assistant tool generates the signatures and wrappers by reading the information in the windows.h
header file, which contains a lot of the function exposed by Windows.
In addition, it also understands the SAL annotations that have now
become standard practice for functions available in Windows, thus making
it easier for the tool to generate accurate signatures and wrappers. Figure 1 shows an example of the tool and the generated code for the CreateFileW API.
Lastly, the RCWCleanupList
command was available but undocumented in SOS 2.0 and is now fully
documented and functional in SOS 4.0. The command displays the global
list of runtime callable wrappers that are no longer in use and are in
the queue to be cleaned up:
0:000> !RCWCleanupList
MTA Interfaces to be released: 0
STA Interfaces to be released: 1